Automating Red Hat Enterprise Linux Patching with Ansible (Part 2 0f 2)
How we automated Red Hat Enterprise Linux OS patching to reduce time-to-production and human error, while improving compliance and risk management posture.
In this second installment of a two-part series, we’ll be going over Phase Two, the build out of standard pre- and post-patching automation, and Phase Three, the build out of application-specific pre- and post-patching automation. Click here for Phase One.
Status Report
With basic patching and reboots automated, a patching session for application environments without any special pre-patching and post-patching activities was reduced from 20 minutes per server, down to 6 minutes per server. This reclamation of time was a welcome improvement to the team, who did most of their patching on evening and weekends (while still spending time in the office during normal business hours).
Having both proven the concept and begun reaping the benefits of just one layer of patching automation, we were carried forward into automating all the standard pre- and post-patching activities every server in every environment was subject to.
Phase Two - Automate Standard Pre- and Post-patcing Activities
The second phase of the project centered around automating a standardized set of pre-patching and post-patching activitites that were universal to all application envionments. We found there was little to do for standard pre-patching that wasn’t already addressed in Phase One. Post-patching tasks, such as compiling a list of errata/patches installed, checking server uptime and emailing a notification to application teams that patching had completed were established as a standard requirement, and required executing directly on the remote hosts, not from the Ansible control node.
Before significant development could begin, a foundational directory structure needed to be defined. Each remote host managed by Ansible has the following directory tree, which corresponds to the home directory of the service account Ansible runs as.
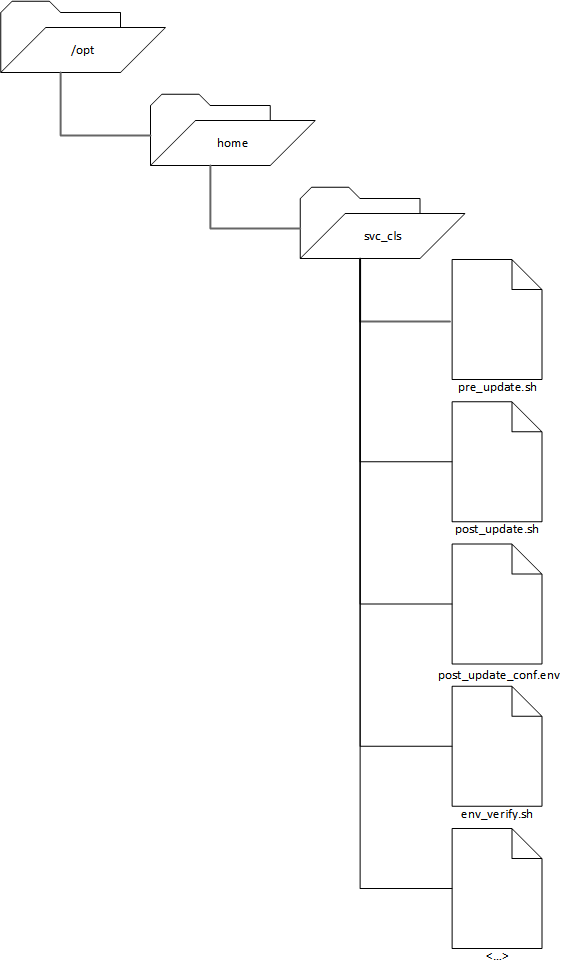
post_update_conf.env and post_update.sh
The following code blocks demonstrate the standard post-patching activities that apply to all application environments. post_update_conf.env is the configuration file source for post_update.sh. An update report, including errata/packages updated, is generated and emailed. If the remote server has its own env_verify.sh script in /opt/encore/home/svc_encore, it will be called from post_update.sh.
/opt/home/svc_cls/post_update_conf.env
email="balcornc@gmail.com"
logFile="/opt/home/svc_cls/post_update.log"
workDir="/opt/home/svc_cls"
snowFlake="/opt/home/svc_cls/env_verify.sh" # snowFlake refers to the environment/
# system-specific validation script
/opt/home/svc_cls/post_update.sh
#!/bin/bash
# @brief script that runs at the end of patching (post-reboot if reboot is
# required) that checks uptime, running kernel, prints latest update
# actions, and performs various system checks defined for a given
# environment
# Load config file
source /opt/home/svc_cls/post_update_conf.env
###########################
# Begin Functions #
function log_msg {
current_time=$(date "+%Y-%m-%d %H:%M:%S.%3N")
log_level=$1
# all arguments except for the first one, since that is the level
log_msg="${@:2}"
echo "[$current_time] $log_level - $log_msg" >> "$logFile"
}
function log_error {
log_msg "ERROR" "$@"
}
Automating Red Hat Enterprise Linuc Patching with Ansible (Part 2 0f 2)
function log_info {
log_msg "INFO " "$@"
}
function log_debug {
log_msg "DEBUG" "$@"
}
function compare_errata {
# Function code adapted from code by R. Paxton
(yum updateinfo list installed | tail -n +3 | grep -v updateinfo | sort > "$workDir"/.current.errata)
#Initialize last errata info if none (display full errar list)
if [[ ! -s "$workDir"/.last.errata ]]; then
touch "$workDir"/.last.errata
fi
# Compare last errata to current errata and only log changes.
comm -3 "$workDir"/.last.errata "$workDir"/.current.errata > "$workDir"/.new.errata
mv -f "$workDir"/.current.errata "$workDir"/.last.errata
# Massage new errata list
if [[ ! -s "$workDir"/.new.errata ]]; then
echo -e "\n========== new errata ===========\n" > "$workDir"/.new.errata
echo "No new errata applied to this host since last update." >> "$workDir"/.new.errata
else
# Remove leading whitespace from comm
sed -i 's/^\s*//' "$workDir"/.new.errata
sed -i '1s/^/\n========== new errata ===========\n\n/' "$workDir"/.new.errata
fi
# Get last yum history info
lastUpdate=$(yum history | grep 'svc_cls\|balcorn' | head -1 | awk '{print $1}')
# Massage update history info
yum history info "$lastUpdate" > "$workDir"/.yum.history
echo -e "\n========== last update history ===========\n" >> "$workDir"/.new.errata
cat "$workDir"/.yum.history >> "$workDir"/.new.errata
cat "$workDir"/.new.errata >> "$logFile"
}
# End Functions #
###########################
###########################
# Begin Body #
errorCheck=0
cat /dev/null > "$logFile"
log_info "========================================================"
log_info "= Post-update status for $HOSTNAME"
log_info "========================================================"
log_info "Running Kernel: "
result=$(uname -r)
log_info "${result}"
log_info "System Uptime: "
result=$(uptime)
log_info "${result}"
log_info ""
log_info "========================================================"
log_info "= Update history:"
log_info "========================================================"
# Collect and clean up update information
compare_errata
# Execute environment/system-specific validation script if it exists
if [ -f "$snowFlake" ]; then
. "$snowFlake"
errorCheck=$?
fi
# Final status of healthchecks - prepend to top of logFile
if [ ${errorCheck} != 0 ]; then
statusMsg="STATUS: ERROR: Something went wrong. Please review results"
sed -i "1s/^/$statusMsg\n\n/" "$logFile"
else
statusMsg="STATUS: OK"
sed -i "1s/^/$statusMsg\n\n/" "$logFile"
fi
/bin/mail -s "Post-patching report for $HOSTNAME" "$email" < "$logFile"
Status Report
By the time patching automation efforts reached the conclusion of Phase Two, roughly 75% of our customer’s RHEL 6 and 7 server infrastructure was being patched fully through Ansible, including sending communication emails and post-patching reports. This cleared the way for the final, albeit most complex push: developing and implementing the automation forcustom pre- and post-patching activities. These custom activities were addressed on a per application environment basis and required significant coordination with our customer’s application teams.
Phase Three - Automate Application/Host-specific Pre- and Post-patching Activities
In Phase Three, application environments with unique pre- and post-patching requirements were addressed. For example, complex pre- patching actions, such as stopping services on web and application servers prior to stopping database services were incorporated. Post-patching validation for application environments where services were required to come up in a prescribed order and validated on one remote host before moving on to the next was also implemented where needed.
The customized pre- and post-patching activities are intended to compliment and extend (and not replace) the standard activities implemented during Phase Two.
pre_update.sh
The following example code block demonstrates stopping the PPM daemon, and validating that the process is down before proceeding. An error is logged if there are issues.
/opt/home/svc_cls/pre_update.sh
#!/bin/bash
# @brief actions required to be conducted before updates are applied
# and/or servers are rebooted.
logFile="/tmp/pre_update.log"
###########################
# Begin Functions #
function log_msg {
current_time=$(date "+%Y-%m-%d %H:%M:%S.%3N")
log_level=$1
# all arguments except for the first one, since that is the level
log_msg="${@:2}"
echo "[$current_time] $log_level - $log_msg" >> $logFile
}
function log_error {
log_msg "ERROR" "$@"
}
function log_info {
log_msg "INFO " "$@"
}
function log_debug {
log_msg "DEBUG" "$@"
}
# End Functions #
###########################
###########################
# Begin Body #
errorCheck=0
cat /dev/null > $logFile
log_info "========================================================"
log_info "= Pre-update status for $HOSTNAME"
log_info "========================================================"
# Stop PPM
(su - ppmadmin -c 'cd /home/ppmadmin/eppm_staging/bin && /home/ppmadmin/eppm_staging/bin/kStop.sh -now -user admin -password admin - name eppm_stagingu1')
result=$(ps -ef | grep -i DNAME | grep -v grep | wc -l)
count=0
# if DNAME process is still running, PPM has not stopped.
while [ "$result" != 0 ] && [ $count -lt 9 ]; do
sleep 20
result=$(ps -ef | grep -i DNAME | grep -v grep | wc -l)
count=$((count + 1))
done
# if PPM hasn't stopped by now, manual intervention/review will be necessary.
if [ "$result" != 0 ] && [ $count -ge 9 ]; then
log_error "PPM has NOT stopped"
errorCheck=1
else
log_info "PPM has stopped successfully"
fi
# Final status of healthchecks
if [ ${errorCheck} != 0 ]; then
statusMsg="STATUS: ERROR: Something went wrong. Please review results"
sed -i "1s/^/$statusMsg\n\n/" $logFile
else
statusMsg="STATUS: OK"
sed -i "1s/^/$statusMsg\n\n/" $logFile
fi
env_verify.sh
In this example code block, the PPM daemon is started manually by the script. The application team was not comfortable with configuring PPM to come up on boot. If the application fails to start, error information is returned to post_update.sh, from which env_verify.sh was called.
/opt/home/svc_cls/env_verify.sh
#!/bin/bash
# @brief environment-/system-specific script to be called from post_update.sh
# returns 0 or 1 value to $errorCheck in post_update.sh for overall
# status to be emailed out upon script conclusion. This script
# will contain environment-specific verification commands.
###########################
# Begin Body #
errorCheck=0
log_info "========================================================"
log_info "= Environment-specific starts and checks"
log_info "========================================================"
# Start PPM
(su - ppmadmin -c 'cd /home/ppmadmin/eppm_staging/bin && /home/ppmadmin/eppm_staging/bin/kStart.sh -name eppm_stagingu1')
result=$(grep -c '*** Ready!' /home/ppmadmin/eppm_staging/server/eppm_stagingu1/log/serverLog.txt)
count=0
# Watch PPM serverLog.txt file for a couple minutes to make sure it comes up before continuing
while [ "$result" -lt 1 ] && [ "$count" -lt 9 ]; do
sleep 20
result=$(grep -c '*** Ready!' /home/ppmadmin/eppm_staging/server/eppm_stagingu1/log/serverLog.txt)
count=$((count + 1))
done
# If PPM hasn't started by now, manual intervention/review will be necessary
if [ "$result" -lt 1 ] && [ "$count" -ge 9 ]; then
log_error "PPM has NOT started"
errorCheck=1
else
log_info "PPM has started successfully"
fi
return $errorCheck
Conclusion
After completing all three phases of automation, patching for 95% of our customer’s application environments is fully automated. The only effort required is to execute the playbooks during scheduled patching windows. The remaining 5% of environments that are not fully automated are made up of special cases, or are in isolated network segments it was deemed to costly to pursue full automation of; however, even in those cases, pre-patching and post-patching activities have been scripted to the highest degree possible.
Prior to this project, manual patching took up to 20 minutes per server, and an administrator could juggle up to two servers at a time, patching up to 6 servers per hour. Leveraging Ansible to automate patching and its related tasks takes on average 6 minutes per server. Ansible is currently configured to patch up to 5 remote hosts simultaneously - up to 30 servers per hour or a 500% average performance increase! observed over the past 5 months.
While we’re constantly looking for ways to improve patching automation, and incorporate greater functionality and reporting where it makes sense to do so, we’re absolutely thrilled with the results we’ve seen from this initial project. Reach out to us if you’d like to learn more about how Encore Technologies could help you realize similar benefits to your RHEL/Linux patching process.
-Brian
Share this post
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Email